
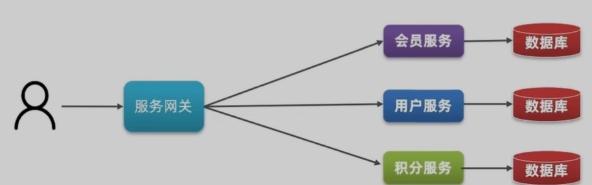
微服务
微服务
1.认识微服务
微服务是一种经过良好架构设计的分布式架构方案,微服务架构特征:
- 单一职责:微服务拆分粒度更小,每一个服务都对应唯一的业务能力,做到单一职责,避免重复业务开发
- 面向服务:微服务对外暴露业务接口
- 自治:团队独立、技术独立、数据独立、部署独立
- 隔离性强:服务调用做好隔离、容错、降级,避免出现级联问题
单体架构特点?
- 简单方便,高度耦合,扩展性差,适合小型项目。例如:学生管理系统
分布式架构特点?
- 松耦合,扩展性好,但架构复杂,难度大。适合大型互联网项目,例如:京东、淘宝
微服务:一种良好的分布式架构方案
- 优点:拆分粒度更小、服务更独立、耦合度更低
- 缺点:架构非常复杂,运维、监控、部署难度提高
2.服务远程调用
基于java通过RestTemplate发送Http请求
1、注册restTemplate到Spring容器

2、使用restTemplate发送Http请求

3.Eureka(注册中心)
提供者与消费者
- 服务提供者:一次业务中,被其它微服务调用的服务。(提供接口给其它微服务)
- 服务消费者:一次业务中,调用其它微服务的服务。(调用其它微服务提供的接口)
一个服务既可以是服务消费者也可以是服务消费者,两者是相对的。
eureka的作用
1、消费者该如何获取服务提供者具体信息?
- 服务提供者启动时向eureka注册自己的信息
- eureka保存这些信息
- 消费者根据服务名称向eureka拉取提供者信息
2、如果有多个服务提供者,消费者该如何选择?
- 服务消费者利用负载均衡算法,从服务列表中挑选一个
3、消费者如何感知服务提供者健康状态?
- 服务提供者会每隔30秒向EurekaServer发送心跳请求,报告健康状态
- eureka会更新记录服务列表信息,心跳不正常会被剔除
- 消费者就可以拉取到最新的信息
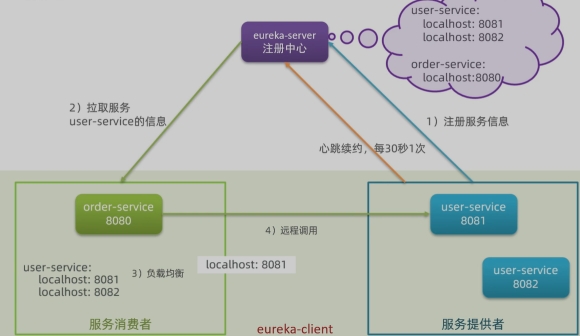
4、在Eureka架构中,微服务角色有两类:
- EurekaServer:服务端,注册中心
- 记录服务信息
- 心跳监控
- EurekaClient:客户端
- Provider:服务提供者,例如案例中的user-service
- 注册自己的信息到EurekaServer
- 每隔30秒向EurekaServer发送心跳 - consumer:服务消费者,例如案例中的order-service
- 根据服务名称从EurekaServer拉取服务列表
- 基于服务列表做负载均衡,选中一个微服务后发起远程调用
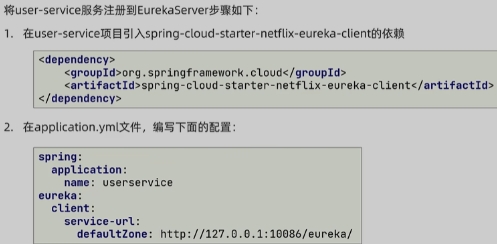
4.服务注册
引入依赖
1 | <dependency> |
配置yml
拉取服务
服务拉取是基于服务名称获取服务列表,然后在对服务列表做负载均衡
1、修改OrderService的代码,修改访问的url路径,用服务名代替ip、端口:
1 | String url = "http://userservice/user/"+ order.getUserId(); |
2、在order-service项目的启动类OrderApplication中的RestTemplate添加负载均衡注解:
1 |
|
总过程
1、搭建EurekaSerer
- 引入eureka-server依赖
- 添加@EnableEurekaServer注解
- 在application.yml中配置eureka地址
2、服务注册
- 引入eureka-client依赖
- 在application.yml中配置eureka地址
3、服务发现
- 引入eureka-client依赖
- 在application.yml中配置eureka地址
- 给RestTemplate添加@LoadBalanced注解
- 用服务提供者的服务名称远程调用
问题:Springcloud使用eureka客户端报错:
com.sun.jersey.api.client.ClientHandlerException: java.net.ConnectException:
解决方案:yml文件层级出错,改正即可
6.Ribbon负载均衡
负载均衡流程

负载均衡策略
通过定义IRule实现可以修改负载均衡规则,有两种方式:
1、代码方式:在order-service中的OrderApplication类中,定义一个新的IRule:
1 |
|
2、配置文件方式:在order-service的application.yml文件中,添加新的配置也可以修改规则:
1 | userservice: |
总结
- Ribbon负载均衡规则
- 规则接口是IRule
- 默认实现是ZoneAvoidanceRule,根据zone选择服务列表,然后轮询
- 负载均衡自定义方式
- 代码方式:配置灵活,但修改时需要重新打包发布
- 配置方式:直观、方便,无需重新打包发布但是无法做全局配置
- 饥饿加载
- 开启饥饿加载
- 指定饥饿加载的微服务名称
7.Nacos注册中心
启动服务
1 | startup.cmd -m standalone |
访问
1 | 在浏览器输入地址:http://127.0.0.1:8848/nacos 即可: |
导入依赖包
1 | <-- 父工程 --> |
配置yml文件
1 | //客户端 |
集群分级存储服务
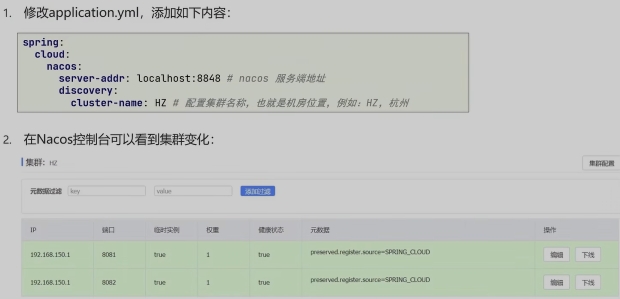
优先同集群负载均衡访问策略
- NacosRute负载均衡策略
- 优先选择同集群服务实例列表
- 本地集群找不到提供者,才去其它集群寻找,并且会报警告
- 确定了可用实例列表后,再采用随机负载均衡挑选实例
- 实例的权重控制
- Nacos控制台可以设置实例的权重值,
- 0~1之间同集群内的多个实例,
- 权重越高被访问的频率越高权重设置为0则完全不会被访问
- Nacos环境隔离
- namespace用来做环境隔离
- 每个namespace都有唯一id不同
- namespace下的服务不可见
8.Nacos配置中心
统一配置管理
- 配置获取步骤:


- pom文件中引入配置依赖
1 | <!--nacos配置管理客户端依赖 --> |
- 对应微服务模块导入配置文件
1 | bootstrap.yml文件 |
- 读取配置文件
1 | 1、Controller中加入注解 //动态刷新配置,配置热更新、 |
- Nacos配置更改后,微服务可以实现热更新,方式:
- 通过@Value注解注入,结合@RefreshScope来刷新
- 通过@ConfigurationProperties注入,自动刷新
- 注意事项:
- 不是所有的配置都适合放到配置中心,维护起来比较麻烦
- 建议将一些关键参数,需要运行时调整的参数放到nacos配置中心,一般都是自定义配置
- 微服务会从nacos读取的配置文件:
- [服务名]-[spring.profile.active].yaml,环境配置
- [服务名].yaml,默认配置,多环境共享
- 优先级:
[服务名]-[环境].yaml>[服务名].yaml>本地配置
Nacos集群搭建步骤:
- 搭建MySQL集群并初始化数据库表
- 下载解压nacos
- 修改集群配置(节点信息)、数据库配置
- 分别启动多个nacos节点
- nginx反向代理
9.Feign (Http客户端,用于发送Http请求)
1、 引入依赖
1 | <!--feign依赖包--> |
2、 启动类上加@EnableFeignClients注解
3、 编写Feign客户端
1 |
|
4、 编写FeignClient接口
5、 使用FeignClient中定义的方法代替RestTemplate
自定义feign配置

- 方式一:在配置文件中配置
1 | feign: |
- 方式二:java代码方式,需要先声明一个Bean
1 | public class FeignClientConfiguration{ |
- 而后如果是全局配置,则把它放到@EnableFeignClients这个注解中:
1 |
- 如果是局部配置,则把它放到@FeignClient这个注解中:
1 |
Feign的日志级别
- 级别从低到高分为:
- NONE:默认的,不记录任何日志
- BASIC:仅记录请求方法、URL、响应状态码及执行时间
- HEADERS:在BASIC的基础上,额外记录请求和响应的header
- FULL:在HEADERS的基础上,额外记录请求和响应的body
Feign的日志配置:
- 方式一是配置文件,feign.client.config.xxx.loggerLevel
- 如果xxx是default则代表全局
- 如果xxx是服务名称,例如userservice则代表某服务
- 方式二是java代码配置Logger.Level这个Bean
- 如果在@EnableFeignClients注解声明则代表全局
- 如果在@FeignClient注解中声明则代表某服务
feign性能调优
Feign底层的客户端实现:
- URLConnection:默认实现,不支持连接池
- Apache HttpClient:支持连接池
- OKHttp:支持连接池
因此优化Feign的性能主要包括:
使用连接池代替默认的URLConnection日志级别,最好用basic或none
- 引入依赖
1 | <!--httpClient的依赖--> |
- 设置配置
1 | feign: |
Feign的优化:
1.日志级别尽量用basic
2.使用HttpClient或OKHttp代替URLConnection引入feign-httpClient依赖,配置文件开启httpClient功能,设置连接池参数
- Feign的最佳实践:
- 让controller和FeignClient继承同一接口
- 将FeignClient、POJO、Feign的默认配置都定义到一个项目中,供所有消费者使用
- 当定义的FeignClient不在SpringBootApplication的扫描包范围时,这些FeignClient无法使用。有两种方式解决:
- 方式一:指定FeignClient所在包
1 |
- 方式二:指定FeignClient字节码
1 | GEnableFeignClients(clients={UserClient.class}) |
10.Gateway网关
-
网关的作用:
1,对用户请求做身份认证、权限校验
2,将用户请求路由到微服务,并实现负载均衡
3,对用户请求做限流 -
搭建网关服务:
网关本身也属于一个微服务,因此需要注册到Nacos服务发现中
1、新建一个微服务,引入依赖
1 | <!--网关依赖--> |
2、配置路由,和nacos地址
1 | server: |
3、流程:

路由断言工厂

过滤器
- 全局过滤器 GlobalFilter

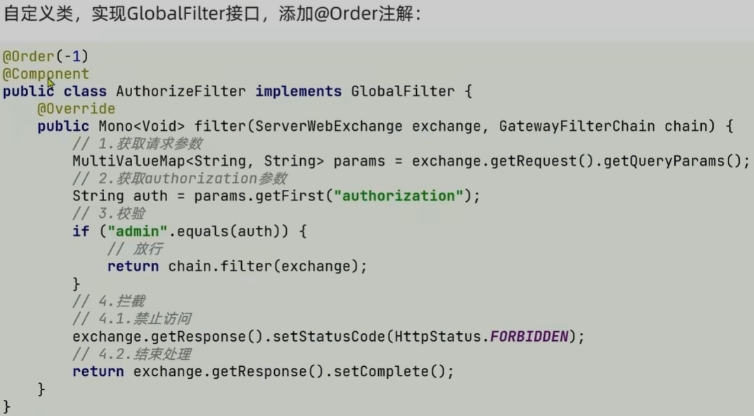
全局过滤器的作用是什么?
1,对所有路由都生效的过滤器,并且可以自定义处理逻辑
实现全局过滤器的步骤?
1,实现GlobalFilter接口
2,添加@Order注解或实现Ordered接口
3,编写处理逻辑
4、过滤器执行顺序
路由过滤器、defaultFilter、全局过滤器的执行顺序?
1,order值越小,优先级越高
2,当order值一样时,顺序是defaultFilter最先,然后是局部的路由过滤器,最后是全局过滤器
5、网关的CORS跨域配置
1 | globalcors: # 全局的跨域处理 |
11.Docker
原理
1、Docker是一个快速交付应用、运行应用的技术:
- 可以将程序及其依赖、运行环境一起打包为一个镜像可以迁移到任意Linux操作系统
- 运行时利用沙箱机制形成隔离容器,各个应用互不干扰
- 启动、移除都可以通过一行命令完成,方便快捷
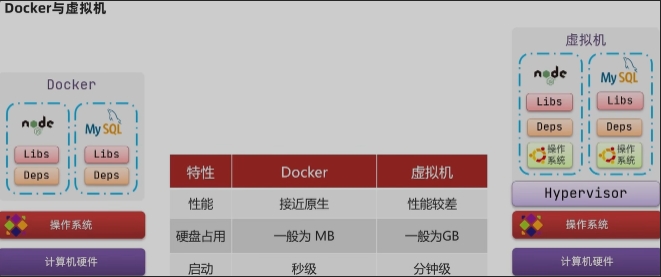
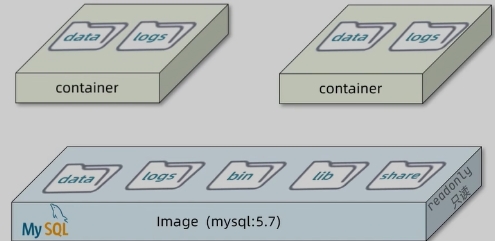
镜像与容器
镜像(Image): Docker将应用程序及其所需的依赖、函数库、环境、配置等文件打包在一起,称为镜像。
容器(Container): 镜像中的应用程序运行后形成的进程就是容器,只是Docker会给容器做隔离,对外不可见。
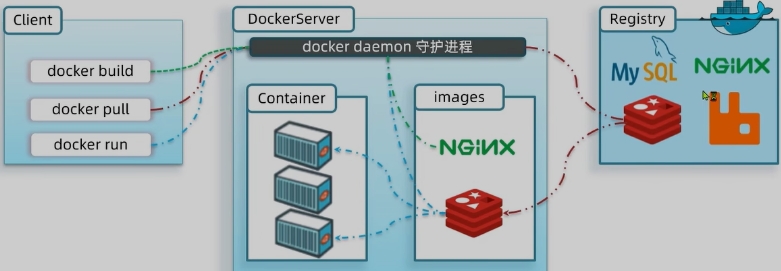
Docker架构
Docker是一个CS架构的程序,由两部分组成:
- 服务端(server):Docker守护进程,负责处理Docker指令,管理镜像、容器等
- 客户端(client):通过命令或RestAPI向Docker服务端发送指令。可以在本地或远程向服务端发送指令
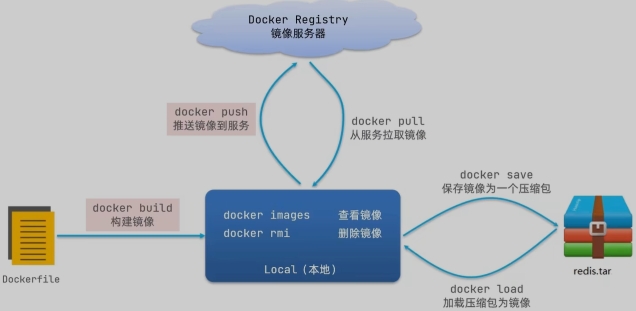
1,镜像:
将应用程序及其依赖、环境、配置打包在一起2,容器
镜像运行起来就是容器,一个镜像可以运行多个容器3,Docker结构:
服务端:接收命令或远程请求,操作镜像或容器客户端:发送命令或者请求到Docker服务端4,DockerHub :
一个镜像托管的服务器,类似的还有阿里云镜像服务,统称为DockerRegistry
Docker镜像命令
1 | systemctl start docker //启动Docker |
Docker容器命令

1 | docker run //创建并启动容器 |
docker run --name containerName -p 80:80 -d nginx
命令解读:
- docker run:创建并运行一个容器
- –name:给容器起一个名字,比如叫做mn
- -p:将宿主机端口与容器端口映射,冒号左侧是宿主机端口,右侧是容器端口
- -d:后台运行容器
- nginx:镜像名称,例如nginx
docker exec -it mn bash
命令解读:
- docker exec:进入容器内部,执行一个命令
- -it:给当前进入的容器创建一个标准输入、输出终端,允许我们与容器交互
- mn:要进入的容器的名称
- bash:进入容器后执行的命令,bash是一个linux终端交互命令
1 | docker logs -f 镜像名 //持续跟踪日志 |
Docket数据卷命令
数据卷:是一个虚拟目录,指向宿主机文件系统中的某个目录
作用:将容器与数据分离,解耦合,方便操作容器内数据,保证数据安全
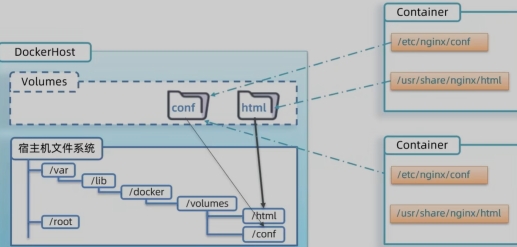
1、常见数据卷命令
1 | //创建数据卷 |
2、挂载数据卷并与容器相连接
1 | docker run: 就是创建并运行容器 |
数据卷挂载方式对比

- docker run的命令中通过-v参数挂载文件或目录到容器中:
-v volume名称:容器内目录
-v宿主机文件:容器内文件
-v宿主机目录:容器内目录 - 数据卷挂载与目录直接挂载的
- 数据卷挂载耦合度低,由docker来管理目录,但是目录较深,不好找
- 目录挂载耦合度高,需要我们自己管理目录,不过目录容易寻找查看
镜像结构
镜像是分层结构,每一层称为一个Layer
- Baselmage层:包含基本的系统函数库、环境变量、文件系统
- Entrypoint:入口,是镜像中应用启动的命令
- 其它:在Baselmage基础上添加依赖、安装程序、完成整个应用的安装和配置
自定义镜像
Dockerfile就是一个文本文件,其中包含一个个的指令(Instruction),用指令来说明要执行什么操作来构建镜像。每
-个指令都会形成一层Layer。
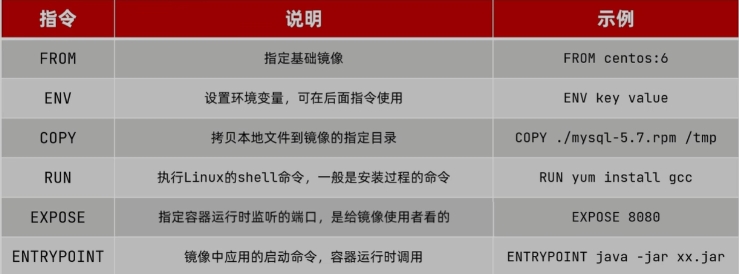
1 | 1.Dockerfile的本质是一个文件,通过指令描述镜像的构建过程 |
DockerCompose
- Docker Compose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器
- Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。
1 | systemctl start docker //启动Docker |
Docker镜像仓库
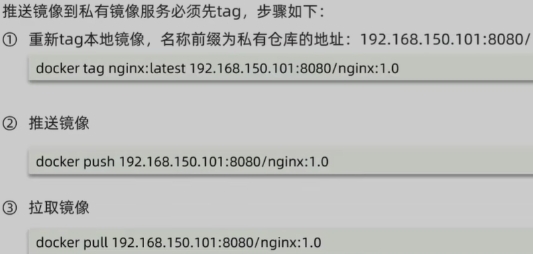
- 推送本地镜像到仓库前都必须重命名(docker tag)镜像,以镜像仓库地址为前缀
- 镜像仓库推送前需要把仓库地址配置到docker服多的daemon.json文件中,被docker信任
- 推送使用docker push命令
- 拉取使用docker pull命令
12.异步通信
基于Feign同步调用:
同步调用的优点:
- 时效性较强,可以立即得到结果
同步调用的问题:
- 耦合度高
- 性能和吞吐能力下降有额外的资源消耗
- 有级联失败问题
异部调用:
- 也就是说只有支付成功后请求才会被发送到这个服务,如果支付失败,在第一步调用接口时就会返回失败
- 这里要表示的就是,用户只关心支付成功没有,也就是说只关心第一步成功没有
- 至于后面的订单或者是短信通知相对来说不重要了,因为用户知道钱已经给了,如果有问题就再说
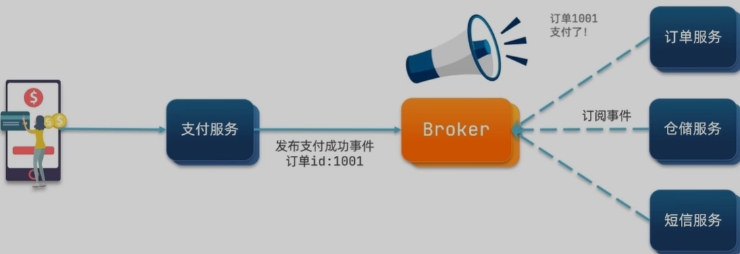
异步通信的优点:
- 耦合度低
- 吞吐量提升
- 故障隔离
- 流量削峰
异步通信的缺点: - 依赖于Broker的可靠性、安全性、吞吐能力
- 架构复杂了,业务没有明显的流程线,不好追踪管理
大多数情况下用的是同步通讯
13.消息队列(MQ)
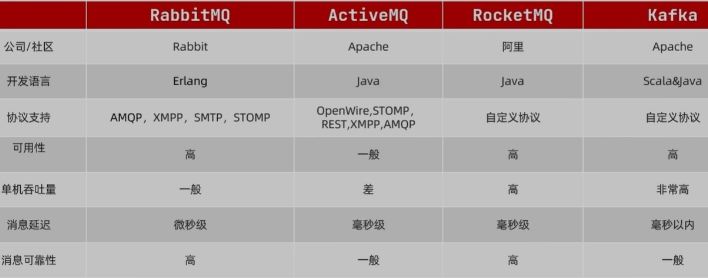
RabbitMQ
1 | //安装 |
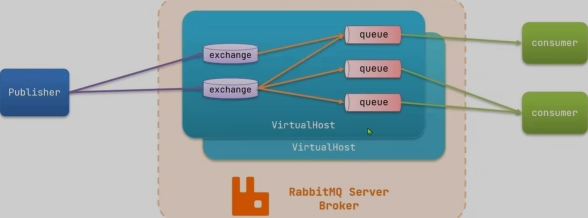
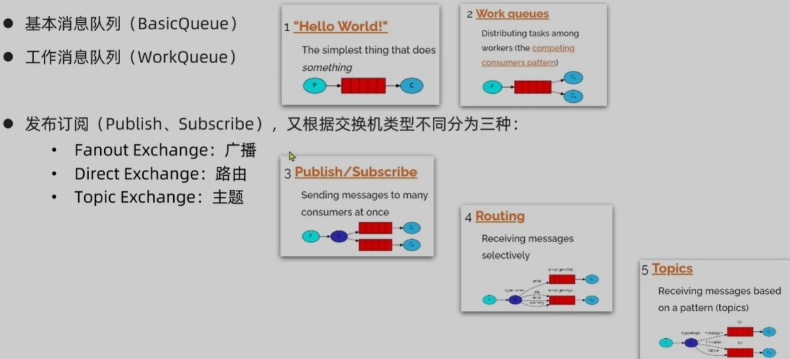
常见消息模型
基本消息队列的消息发送流程:
- 建立connection
- 创建channel
- 利用channel声明队列
- 利用channel向队列发送消息
基本消息队列的消息接收流程:
- 建立connection
- 创建channel
- 利用channel声明队列
- 定义consumer的消费行为handleDelivery()
- 利用channel将消费者与队列绑定
SpringAMQP
- 基本队列BasicQueue
1 | //1,父类中引依赖 |
SpringAMQP如何接收消息?
- 引入amqp的starter依赖
- 配置RabbitMQ地址
- 定义类,添加@Component注解
- 类中声明方法,添加@RabbitListener注解,方法参数接收消息
- 注意:消息一旦消费就会从队列删除,RabbitMQ没有消息回溯功能
- 工作队列WorkQueue
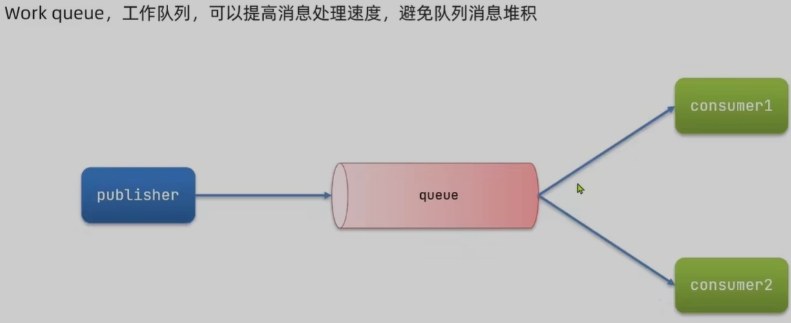
消息预取机制:修改消费者服务yml配置文件中的preFetch的值,可以设置预取消息的上限
1 | spring: |
Publish,Subscribe(发布,订阅模型)
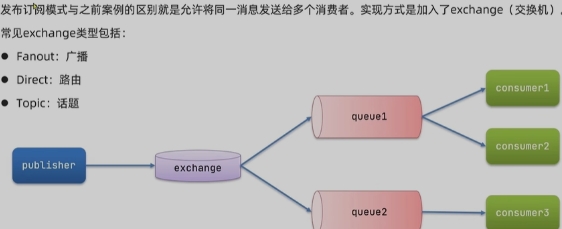
Fanou Exchange 广播
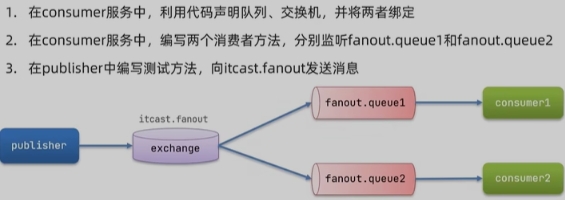
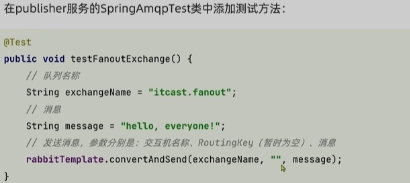
交换机的作用是什么?
- 接收publisher发送的消息
- 将消息按照规则路由到与之绑定的队列
- 不能缓存消息,路由失败,消息丢失
- FanoutExchange的会将消息路由到每个绑定的队列
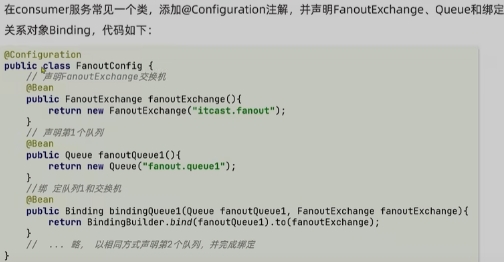
声明队列、交换机、绑定关系的Bean是什么?
- Queue
- FanoutExchange
- Binding
Direct Exchange 路由
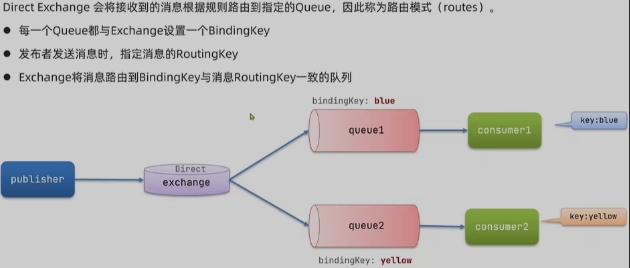
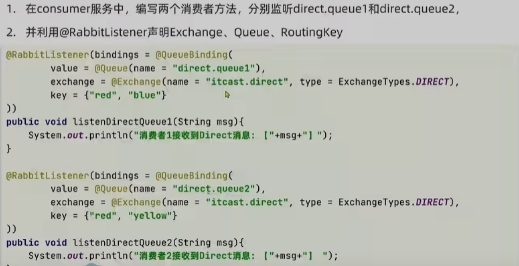
描述下Direct交换机与Fanout交换机的差异?
- Fanout交换机将消息路由给每一个与之绑定的队列
- Direct交换机根据RoutingKey判断路由给哪个队列
- 如果多个队列具有相同的RoutingKey,则与Fanout功能类似
基于@RabbitListener注解声明队列和交换机有哪些常见注解?
- @Queue
- @Exchange
Topic Exchange 话题
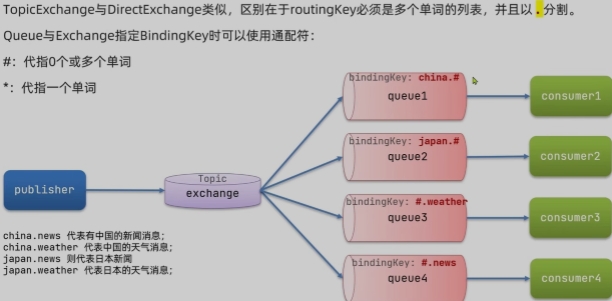
消息转换器
1 | //父工程引入依赖 |
SpringAMQP中消息的序列化和反序列化是怎么实现的?
利用MessageConverter实现的,默认是JDK的序列化
注意发送方与接收方必须使用相同的Messageconverter


